A Case for OSS
Initial Thoughts...

Marc Chagall; ‘L'Écuyère à la lyre’, 1971
Over the weekend, I took the rather belated (especially in the context of the recent developments over at OpenAI) step of reading the now controversial “Situational Awareness” whitepaper by Leopold Aschenbrenner. While the prognoses regarding the rate of development seemed to be of a basis, I felt a note of discomfort when I began to digest the underlying sentiment in Leopold’s proclamations of a soon-to-be fully capable AGI. It wasn’t so much as the geopolitical ramifications that a race for a sentient AGI would entail but rather the underlying sentiment pervading the whitepaper. In short, it was the lack of awareness or rather the brutal sense of blitheness when glossing over the tumultuous ramifications of a fully digested AI that had registered so poorly in me.
Having read the last paragraph, many of the audience will undoubtedly dismiss my following thoughts as the extolling of self-imposed stagnancy, a hallmark of the luddite-esque lethargy that has currently infiltrated the general zeitgeist. However, rather than the accelerationist modus operandi championed by most AI developers, I seek to expound a methodology of transparency and “open-ness” that will enable the foundations of a more pragmatic and nourishing AI. Let me explain.
Ever since I had been a child, honesty had always been my hallmarks. I was never the one to tell white lies, never the one to sugarcoat hurtful truths or to deliberately mislead others. To be “open” and cognizant of my opinions and thoughts had been an imperative for most of my youth, despite the ire I drew from my classmates. Yet, it was for some reason that I had always been reticent in applying such a perspective when understanding the world of commerce. Fascinated with the dastardly exploits of Rockefeller or Mellon for most of my youth, I quickly understood the founding principles of capitalism. Competitive advantages in commercial affairs were to be hidden and protected, safeguarded from the watchful eyes of competitors salivating at the prospect of gobbling up market share.
It was because of this cognitive dissonance, that I initially had a great deal of trouble understanding the recent developments in the software/cloud industry. Despite the revolutionary developments that we saw in the early 2010s and ZIRP era as heralded by the now ubiquitous saying “software is consuming the world” era, tech company valuations continue to tumble. While some attribute these continued struggles to the current macroeconomic climate, one posits that these economic challenges that have instead adjusted our “mental models” to the actual value proposition of these companies.
As the underlying costs of building these applications became cheaper and cheaper (as a flywheel effect of previous software development), we have comme to the realization that with no moat, companies would earn no returns. While this has initially manifested (in both the privates and publics side) in an emphasis on infrastructure-based “hard tech” (eg. American Dynamism), open-source software has also become a topic of much discussion. For reference, we define open source-software (OSS) as software whose underlying source code is openly available for anyone to view, modify, and distribute.
It is in this newfound paradigm that brings us to the increasing adoption of OSS. It is crucial to understand the differences between OSS and CSS (closed source software) models. Rather than the belief that the underlying technology is the edge (historic CSS framework), OSS posits that an edge is developed through the nebulous “moat” that a business possesses. Furthermore, the development of OSS software fosters a deeper relationship between developer and user, enabling the development of new features and resolution of issues. Through open access and usability of underlying data and developmental platforms, users gain a greater understanding of the service, demystifying pricing mechanisms and establishing coherent feedback patterns.
It is through the application of this framework that software effectively becomes “anti-fragile”, better equipping developers to navigate edge cases and sustain innovation. As traditional SaaS companies continue to be buffeted by uncertain macroeconomic conditions, Joseph Jack’s prognosis in 2022 of a world where “open source is eating software faster than software is eating the world” has become prescient. Now competing on bases of network effects and management competence, OSS adoption has unfolded at a rapid pace across the globe, with OSS venture funding ballooning compared to previous years.
As both capital allocators and software developers begin to appreciate the value of community-driven flexibility and scalability that such an approach enables, open source is poised to serve as the appropriate operational model for future software firms.
While it has been just a few years since the unveiling of OpenAI’s ChatGPT model, the explosive growth of model performance has substantiated AI’s viability to act as a catalyst for the development of mankind. With the earliest models just barely capable of understanding large scale inputs, the most advanced models rival the cognitive performances of most highschoolers. Studies even just that certain models are capable of performing above average on standardized tests and of reasoning through complex problems.
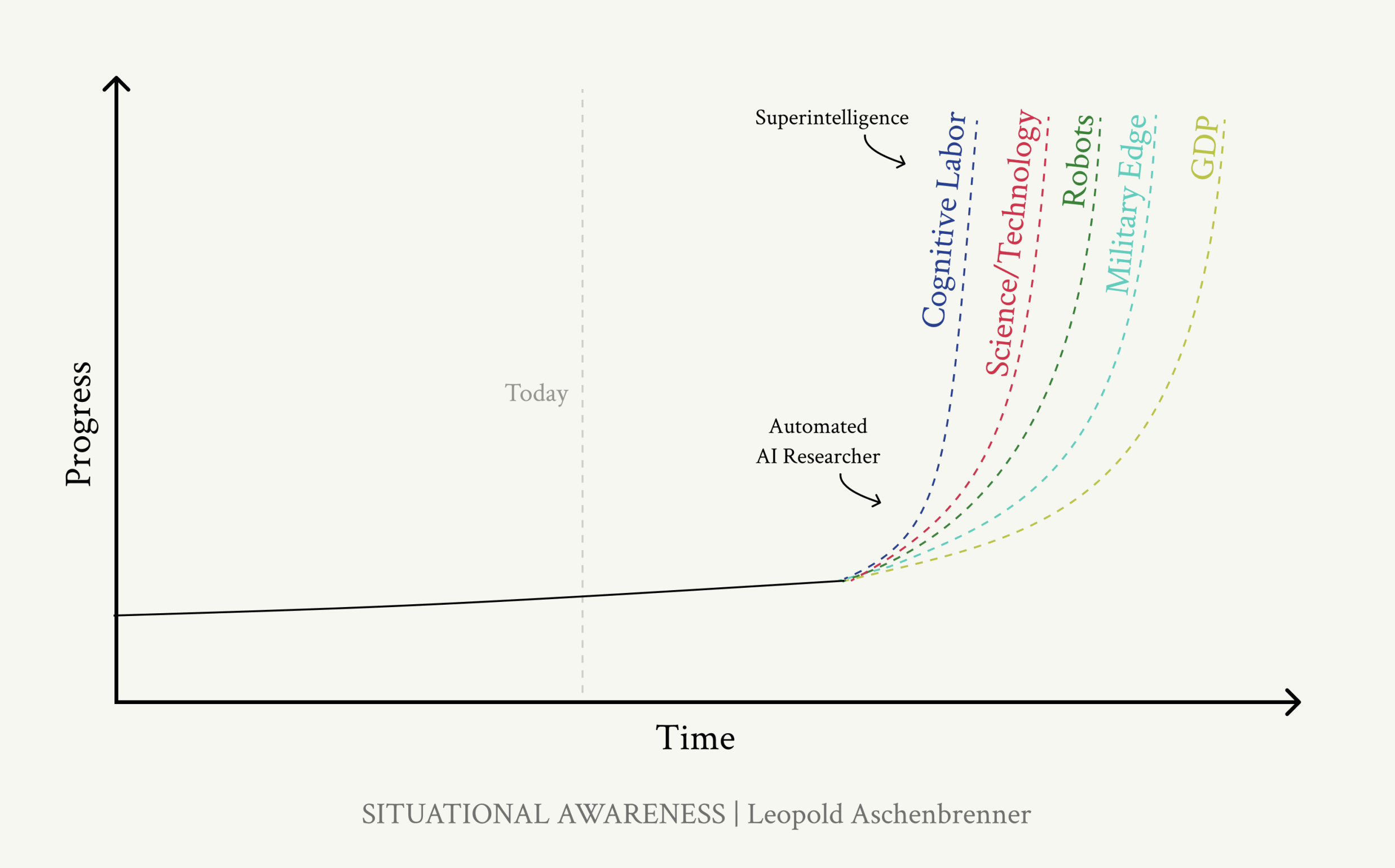
Throughout the tech industry, there is an understandably rich fervor surrounding the prospect of revitalizing the historically antiquated industries such as agriculture and industrials. However, the most worrying implications for the future development of AI would be for the existing socio-governance infrastructures. Despite the blithely ignorant thoughts of the likes of Leopold and and those who desire for accelerated AI development unencumbered by the moors of regulatory approval, the reality is that the opinions of the masses will prove to be the deciding variable in AI’s integration.
The answer to this conundrum lies in the lessons found in the OSS transition. One posits that the implementation of OSS applicability to AI would result in value-rich applications, fostering significantly closer public-private relationships that could help dissuade the public’s mistrust of AI.
However, in a constrast with software, the likes of leading AI developers such as OpenAI and Anthropic have shifted their models from open source to closed source. While the likes of viable competitors such as Nous Research have maintained their stance on open source (thereby giving access to model weights, parameters, and data sets), the vast majority of LLM developers continue to utilize the closed source model. While it isn’t irrational of these developers to rely on CS in an attempt to “maintain” their edge and justify significant CAPEX, one can’t help but wonder the implications of this in the context of AI’s disruption of existing infrastructure.
I firmly believe that the fundamental driver of such dissonance is that of the antiquated economic/commerce-based model of old that we continue to rely. We’ve seen this reflected in the rising concerns of “excessive” datacenter spending and the recent developments happening at OpenAI (having announced the largest funding round in history in addition to having transitioned from a nonprofit into a commercial venture). While it is undeniably clear that the continued innovation of artificial intelligence is a tremendously lucrative venture, many of the developers fail to understand the social implications of artificial intelligence. In the context of AI’s capacity to introduce significant upheavals in the existing order, it is crucial to view this from a moat/social perspective rather than a purely commercial one.
To reiterate, one of the greatest factors that would limit the integration AI would be the general populace, with members of the current population already having voiced complaints regarding AI driven displacement. Furthermore, high profile individuals at the helm of cutting-edge AI labs have already issued worrying premonitions detailing radical changes in job responsibilities and income.
While the vagaries of those in certain industries may be justified, one believes that a significant proportion of the fear can be attributed to a fundamental misunderstanding AI. One way to help dispel such conventions is to introduce visibility and transparency for these models, introducing open-source protocols to data sets, algorithms, and model weights. The utilization of such protocols will help to dispel such misunderstanding, potentially lessening the significant conflict that is due to occur.
One of the most glaring issues that has begun to plague AI development is that of the data wall. Existing LLMs have already been trained on a majority of the inter-web, yet in order for them to continue their trajectory, they need to be fed new sets of quality data which have grown scarcer and scarcer. While the seeds of potentially solutions have begun to percolate, current efforts remain inadequate.
Given the rather insatiable expectations (or rather demands), it is widely expected for existing developers to either voluntarily slow down their developmental efforts or to rely on slip-shod mechanisms to make up for the difference in data quality, two subpar outcomes. Through the enabling of access to data sets and algorithms, viable solutions to this problem may be developed, catalyzing innovation whilst fostering general understanding from the perspective of the populace.
Doing so will introduce the seeds of “anti-fragility”, a term that currently seems alienable to a technology that are routinely subject to “hallucination” and faulty edge case processing. With the likes of Leopold having made substantive claims that even a semi-sentient AGI would be capable of training itself, it is pertinent more than ever to help introduce new eyes to existing infrastructure before it is far too late.
One of the key implications of OSS is that companies no longer rely on underlying source material as the source of sustainable competitive edge, rather looking towards intangible factors. In regard to AI, one can claim that the main differentiating factor is that of transparency of logic patterning and data sources. Rather than choosing to solely evaluate models based on standardized metrics of performance or compute efficiency, the understanding of the integrity + transparency of data sets and algorithms must dictate our judgement of future AI agents.
Instead of adhering to the economic performance-based perspectives of the hold, it is imperative for us adopt a new-found framework regarding integrity and transparency. Not for the sake of stymieing progress as many will choose to do so as AI continues to develop, but to implement the proper foundations for mankind to flourish alongside artificial intelligence.